The Polymath Fallacy: Why Chasing AGI Is the Wrong Strategy for Enterprise AI
By LumaVista Team


Every few months, a new frontier model drops and the tech press runs the same headline: “Is this AGI?” The benchmarks go up. The demos get more impressive. The investors nod sagely about how close we are to artificial general intelligence — the one model that can do everything a human can do, and more.
Meanwhile, a logistics company in Rotterdam has been using a pattern-matching system to flag fraudulent shipment documents since 2003. It doesn’t understand poetry. It can’t write code. It has no opinion on the trolley problem. But it catches €11 million in fraud per year, and it’s never once needed a philosophical breakthrough to do it.
The AGI race is the enterprise equivalent of searching for a mythical polymath — a single hire who’s simultaneously a world-class researcher, accountant, writer, analyst, engineer, and strategist — instead of just building a great team. It’s not that polymaths don’t exist. It’s that waiting for one is an extraordinarily expensive way to avoid the management problem of coordinating specialists.
This isn’t an anti-AGI argument. The research is valuable — and as we’ll see, it fuels improvements across the entire model ecosystem. But if you’re a CTO or VP of Engineering waiting for AGI before you invest seriously in AI, you’re making the most expensive hire you’ll never need.
The capabilities you actually need? Most of them crossed the production-useful threshold years ago. Some crossed it decades ago. And the gap between “what’s available now” and “what enterprises are actually using” has nothing to do with model intelligence — it has everything to do with architecture.
AI has been doing production-grade work since the 1960s. The breakthrough is not that machines became useful — it is that dozens of capabilities crossed production thresholds at once.
Intelligence is not a single axis
Here’s the cognitive bias at the root of the problem: humans compress a staggeringly diverse set of capabilities into a single word — “smart.”
We do it with people. “She’s really smart” could mean she’s a brilliant mathematician, a gifted writer, an intuitive negotiator, or someone who remembers every detail of every conversation she’s ever had. These are completely different cognitive abilities. But we flatten them into one dimension and rank people on it, like height.
We do the same thing with AI models. MMLU scores. Arena rankings. “GPT-5 is smarter than GPT-4.” As if intelligence were a single number you could plot on a line graph and wait for it to cross some magic threshold.
It isn’t. Intellectual work decomposes into discrete capabilities: logical reasoning, creative synthesis, pattern recognition, precise recall, language generation, spatial reasoning, planning under uncertainty. A model that’s extraordinary at chain-of-thought reasoning might be mediocre at precise information extraction. A model that generates beautiful prose might botch a logic puzzle that a much smaller model handles easily.
And here’s the part that breaks the “AI is suddenly useful” narrative: AI has been doing useful, production-grade work since the 1960s. The US Postal Service deployed OCR systems to read handwritten addresses in 1965. That’s not a typo. Sixty years ago, a machine was reading your grandmother’s cursive well enough to route her letters across the country.
Fraud detection systems went into production in the late 1990s. Spam filters — a pattern recognition task — became good enough to use by 1998. DEC’s XCON expert system was saving €37 million per year in the 1980s by configuring VAX computer orders, a reasoning task that previously required senior engineers. Recommendation engines hit their stride around 2006, during the Netflix Prize era.
None of these systems were “smart” in the way we fantasize about AGI being smart. They were specialists. Extremely good at one thing, useless at everything else. And that was enough. More than enough — they generated billions in value precisely because they were scoped to specific problems with well-defined inputs and outputs.
The “AI is suddenly useful” narrative isn’t just misleading. It’s factually wrong. What’s new isn’t the concept of machines doing useful cognitive work. What’s new is the breadth — the number of capabilities that have simultaneously crossed production thresholds. And that’s a coordination opportunity, not a reason to wait for a god-model.

The skill curves are already crossing
If you plotted every major AI capability on a timeline — when it started, when it became production-useful, and where it is now — you wouldn’t see a single line rising toward AGI. You’d see a dozen different curves, each starting at a different point, growing at a different rate, and plateauing at a different ceiling.
Some of these curves crossed the “good enough for production” threshold decades ago and have barely moved since. OCR hit production quality in the 1960s and has been essentially solved since the early 2000s. Recommendation engines peaked around 2015 — the algorithms haven’t changed much, just the data they’re fed. Pattern recognition for fraud and spam has been superhuman since ImageNet in 2015.
Other curves are climbing steeply right now. Code generation barely existed before 2019 and hit production quality with GitHub Copilot in 2021 — it’s on the steepest growth curve of any capability today. Creative generation went from research curiosity (GANs in 2014) to production tool (DALL-E 2, Midjourney) in 2022, and it’s still climbing fast. Natural language processing had a long, slow ramp starting in the early 2000s with basic sentiment analysis and named entity recognition, then went nearly vertical after BERT in 2018 and GPT-3 in 2020.
Reasoning and planning is the curve that gets the most attention right now, and for good reason — it’s the hardest to pin down. Expert systems proved the concept in the 1980s. XCON could reason about computer configurations. Medical diagnosis systems could narrow down conditions from symptoms. But those systems were brittle — they only worked within hand-coded knowledge domains.
Modern reasoning models (o1, R1, chain-of-thought fine-tunes) are generalizing that capability, and the curve is climbing fast. But it hasn’t plateaued yet, and it may not for years.
And then there’s the conversational AI curve — perhaps the most instructive one. ELIZA, the first chatbot, was built in 1966. That’s the same decade as the USPS OCR system. But conversational AI didn’t actually become production-useful until ChatGPT in late 2022. That’s a 56-year gap between “deployed” and “good.” If you’d been waiting for conversational AI to become useful in 1985, you’d have waited almost four decades. But if you needed pattern recognition in 1985, it was already there.

The key insight is in the horizontal threshold bands. Every job function has a capability threshold — a minimum level of performance below which the AI isn’t useful for that task. Data extraction crossed its threshold in the 1960s. Fraud detection crossed in the late 1990s. Research synthesis is crossing right now. Some thresholds haven’t been crossed yet — genuine creative direction, complex negotiation, scientific hypothesis generation at the frontier.
AGI, conceptually, is the point where every curve crosses every threshold simultaneously. It’s the envelope that encompasses all capabilities at superhuman levels. And yes, that envelope is getting closer. But at what cost? Pushing every single capability past every single threshold simultaneously requires exponentially more compute, data, and research than pushing any individual capability past the one threshold your business actually needs.
Most enterprises don’t need every curve to cross every threshold. They need three or four specific capabilities to be good enough for their specific workflows. And for most workflows, those curves crossed years ago.
Most enterprises do not need every capability curve to cross every threshold. They need three or four specific capabilities to be good enough for their specific workflows.
The real cost of the god-model
Here’s the economic absurdity of the polymath approach. When you route every task through a frontier model, you’re paying frontier prices for work that was solved decades ago.
Think about a typical enterprise document-processing pipeline. Roughly 80% of the work is extraction — pulling structured data out of invoices, contracts, receipts, forms. This is a capability that plateaued in the early 2000s. Specialized extraction models handle it with 99%+ accuracy at a fraction of a cent per document.
But if you’re running everything through a frontier LLM because that’s what your vendor offers, you’re paying 50-100x more for equivalent output on a task that doesn’t need reasoning, creativity, or world knowledge. It needs OCR and a schema.
The remaining 20% of the pipeline might genuinely benefit from a frontier model — interpreting ambiguous clauses in a contract, classifying documents by intent rather than keyword, summarizing findings in context. That’s where you want the heavy model. But you’re paying for 100% frontier compute to get 20% frontier value.
The cost ratios are staggering. For bounded extraction tasks, a specialized model costs roughly €0.09 per million tokens. A frontier reasoning model costs €9-14 per million tokens. That’s a 100-150x markup. For tasks where output quality is statistically identical between the two, you’re hiring a Nobel laureate to sort mail.
Latency follows the same pattern. Frontier models are slower — more parameters, more computation per token, longer queue times on shared infrastructure. When 80% of your pipeline is waiting behind tasks that a smaller model could process in milliseconds, your end-to-end latency is dominated by the wrong bottleneck.
Energy consumption compounds the problem. Larger models draw more power per inference. If you care about operational costs — or about sustainability commitments that aren’t purely cosmetic — running a 400B-parameter model on a task that a 7B model handles equally well isn’t just wasteful. It’s architecturally negligent.
There’s also an opportunity cost that doesn’t show up on any dashboard. When every task is queued behind the same frontier model, your pipeline’s throughput is gated by that model’s capacity. Specialized models running on smaller hardware can process bounded tasks in parallel at 10-20x the throughput of a single frontier deployment. You’re not just paying more — you’re going slower while paying more.
The god-model approach doesn’t just cost more. It costs more for worse results on the majority of tasks, because you’ve traded specialization for generality in places where generality adds nothing.

A team needs a manager, not a bigger brain
So if the polymath is a fallacy, what’s the alternative? You build a team and give it a manager.
The resolution to the polymath fallacy isn’t a smarter model. It’s a smarter harness. An orchestration layer that knows which capability each task requires, routes it to the right specialist, composes the outputs, and enforces quality gates along the way. The manager doesn’t need to be brilliant — it needs to be organized.
This is the hybrid architecture pattern applied at the model level. Deterministic procedures handle what’s deterministic: validation, routing, formatting, business rules, budget enforcement. Probabilistic models handle what’s probabilistic: interpretation, generation, reasoning, classification. The orchestration layer decides who does what.
In practice, this looks like a directed acyclic graph — a DAG. Each node in the graph represents a task. Each task has a capability profile: does it need reasoning? Extraction? Generation? Speed? A large context window? The orchestration layer matches that profile against available models and routes accordingly.
A research workflow might decompose like this: a planning node (needs strong reasoning, runs once) fans out into five search nodes (need speed, run in parallel) that feed into analysis nodes (need reasoning, moderate context) that converge into a synthesis node (needs large context, good prose). The planner gets a frontier reasoning model. The search nodes get a fast 14B model. The analysis gets a mid-tier reasoning model. The synthesis gets a large-context writer model.
Same workflow. Four different models. Total cost: a fraction of what an all-frontier approach would charge. Total quality: higher, because each model is operating within its sweet spot instead of being stretched across tasks it wasn’t optimized for. This is the same principle behind multi-model research stacks — the model that’s brilliant at planning is terrible at the rapid-fire judgment calls a searcher needs to make.
The analogy to human organizations is exact. A well-run consulting firm doesn’t send partners to do associate-level research. Partners set strategy. Associates gather data. Analysts crunch numbers. A project manager keeps the timeline and budget on track. No one in the chain needs to be a polymath. They need to be good at their role, and the coordination needs to be tight.
The orchestration layer also handles the things no model can handle alone: retry logic, budget ceilings, data sovereignty routing, audit logging, timeout management, graceful degradation. These aren’t AI problems. They’re engineering problems. And they need engineering solutions — deterministic code that guarantees behavior rather than predicting it.
The polymath fallacy persists because it’s simpler to imagine one brilliant entity handling everything than to design a system where specialists collaborate. But “simpler to imagine” and “simpler to build” aren’t the same thing. And in production, the team with a good manager beats the lone genius every time. If you’ve been wondering what the org chart looks like when you stop waiting for the polymath and start designing around the buckets, The New Org Chart: Who’s Good at What is the operational counterpart to this argument in our series on the post-spreadsheet business.
Specialized extraction at €0.09 per million tokens versus frontier reasoning at €9-14 — that is a 100-150x markup to get statistically identical output on bounded tasks.
Show your work
There’s a second cost to the god-model approach that doesn’t show up on the invoice: you can’t see what it’s doing.
When a monolithic model produces an output, you get a result. Maybe it’s right. Maybe it’s confidently wrong. You can ask it to explain its reasoning, and it’ll generate an explanation — but that explanation is itself generated from opaque weights.
The chain-of-thought isn’t a window into the model’s actual computation. It’s the model’s best guess at what a plausible reasoning process would look like. When the model hallucinates a conclusion, the chain-of-thought hallucinates a justification. Confidently.
“Thinking tokens” create an illusion of transparency. You see words that look like reasoning — “Let me consider the evidence… On one hand… On the other hand…” — and it feels like watching someone think. But you’re watching a language model generate text that resembles deliberation. The internal process that actually produced the conclusion is a matrix multiplication across billions of parameters, and no amount of chain-of-thought prompting makes that visible.
This matters more than most people realize. When a model gets the answer right, the generated reasoning looks convincing. When the model gets the answer wrong, the generated reasoning looks equally convincing. The chain-of-thought doesn’t degrade gracefully — it doesn’t get more uncertain or hedging when the underlying computation is shaky. It hallucinates confidence because confidence is what reasoning text looks like in the training data.
Now compare that with an orchestrated system. Every step is a node in a visible graph. The planner’s output — the research plan — is an inspectable artifact. You can read it. You can disagree with it.
You can see that the planner decided to investigate three threads and skipped a fourth. Each search node’s results are logged: what was queried, what was returned, what was selected and what was discarded. The analysis node’s inputs are traceable to specific sources. The synthesis node’s output carries provenance — every claim maps back through the graph to the search result that supports it.
When something goes wrong — and in production, things go wrong — the diagnostic process is completely different. With a monolithic model, you stare at the output and guess. Maybe the prompt was wrong. Maybe the context was too long. Maybe the model had a bad day (literally — inference variance is real). You can’t see inside.
With an orchestrated graph, you look at the node that produced the bad output. You check its inputs. You trace the data path upstream. You find the specific point where the pipeline diverged from reality.
Transparency is architectural, not cosmetic. It isn’t a feature you bolt on at the end — it’s a property you get for free when you decompose a monolithic process into visible, inspectable steps. You don’t get explainability by asking a black box to explain itself. You get it by building a system where every step is already exposed.

For regulated industries — finance, healthcare, legal, government — this isn’t optional. “The AI said so” isn’t an acceptable answer to an auditor. “Node 7 classified this document as high-risk based on these three extracted clauses, which were verified against the regulatory database in node 9, and the classification triggered the escalation workflow in node 11” — that’s an answer an auditor can work with.
Selecting for the job, not the benchmark
If you’re a CTO evaluating AI for your organization, the polymath fallacy shows up as a specific failure mode: selecting models based on general benchmarks instead of task-specific performance.
MMLU, GPQA, HumanEval, Arena Elo — these benchmarks measure general capability across broad domains. They’re useful for comparing models at a high level. They’re almost useless for predicting whether a model will perform well on your specific extraction pipeline, your specific document classification schema, your specific research synthesis workflow.
A model that scores 90% on MMLU might score 60% on your contract clause extraction task, while a model that scores 75% on MMLU nails the extraction at 98% because it was fine-tuned on legal documents. The general benchmark told you the wrong thing. It’s like hiring a software engineer based on their SAT score — technically correlated with intelligence, practically useless for predicting whether they can ship production code.
Here’s a practical framework for model selection that sidesteps the fallacy:
Map your workflows to capability requirements. Take your top five AI use cases and decompose each one into discrete tasks. For each task, identify the primary capability: extraction, classification, reasoning, generation, search, summarization. You’re building a capability matrix, not shopping for a single product.
Evaluate against task-specific benchmarks. Don’t rely on MMLU. Build a test set from your actual data. Take 100 representative inputs for each task, run them through candidate models, and score the outputs against ground truth. This takes a day of work and saves months of regret.
Right-size aggressively. For each task in your matrix, find the smallest model that meets your quality threshold. If a 7B model achieves 97% accuracy on your extraction task and a 70B model achieves 98%, the 7B model is the right choice — unless that 1% matters enough to justify 10x the cost and 5x the latency.
Build fallback chains. Route tasks to the cheapest appropriate model first. If confidence is below threshold, escalate to the next tier. Most tasks resolve at the first tier. You pay frontier prices only for genuinely frontier problems.
Measure continuously. Model quality isn’t static. New releases, fine-tunes, and quantization improvements shift the landscape every few months. The model that was best for your use case six months ago might not be today. Automated evaluation pipelines catch this drift before your users do.
The compounding advantage of this approach is real. Each task-specific optimization saves a small amount per inference. Across thousands of daily inferences, across five or ten different task types, across months of operation, those small savings compound into significant structural cost advantages — and usually better quality, because each task gets the right specialist instead of a generalist.
This is also the antidote to vendor lock-in. When your architecture assumes a single model from a single provider, switching costs are enormous — every prompt, every integration, every quality threshold is tuned to that one model’s behavior. When your architecture is model-agnostic at the task level, swapping out one specialist for a better one is a configuration change. The model market gets more competitive every quarter. An architecture that can take advantage of that competition is an architecture that gets cheaper and better over time without any effort from you.

The quiet revolution
The AGI race isn’t a waste. Far from it. Every frontier model advance pushes the entire ecosystem forward. The reasoning breakthroughs in GPT-4 trickled down into open-source models within months. The efficiency techniques developed for trillion-parameter models made 7B models viable for tasks that used to require 70B. The AGI research labs are the basic science departments of the AI industry — they push boundaries that everyone else benefits from.
But the companies extracting value from AI today aren’t waiting for the polymath. They’re building orchestrated teams of specialists. They’re routing extraction tasks to extraction models, reasoning tasks to reasoning models, and generation tasks to generation models. They’re wrapping the whole thing in deterministic code that enforces budgets, guarantees data sovereignty, and produces audit trails that their compliance teams can actually use.
The quiet revolution isn’t happening at the frontier. It’s happening in the orchestration layer — the boring, unglamorous work of figuring out which model to use for which task, how to compose their outputs, and how to make the whole system transparent and auditable.
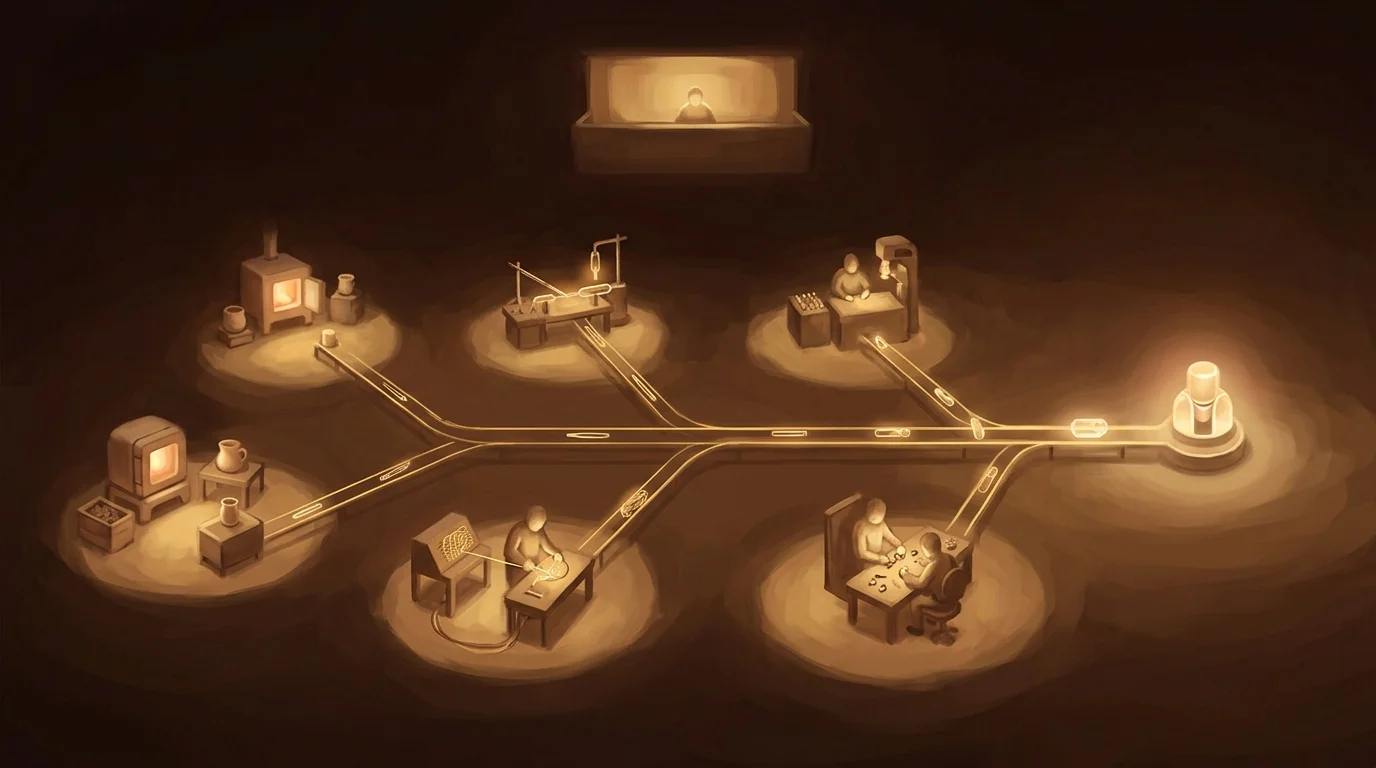
This is what we built at LumaVista. Not a bigger brain — a better manager. An orchestration engine that composes multiple specialized models by capability profile, not by hype cycle. Every research run produces a visible, traceable decision graph where you can inspect every node, trace every data path, and audit every decision. Deterministic code enforces the guarantees that probabilistic models can’t: budgets, jurisdiction, completeness, provenance.
The polymath is a beautiful idea. But you don’t need a beautiful idea. You need results.
What to do now:
-
Audit your current AI spend. How much are you paying for frontier-model inference on tasks that a specialized model handles equally well? The answer is almost always “more than you think.”
-
Decompose your top workflows. Pick your three most important AI-powered processes. Break each one into discrete tasks. Label each task with its primary capability requirement.
-
Run task-specific evaluations. For each task, test at least three models at different size tiers. Measure quality, latency, and cost. You’ll find that smaller models match frontier quality on most tasks.
-
Build the routing layer. Even a simple capability-based router — “extraction tasks go to model A, reasoning tasks go to model B” — delivers immediate cost and quality improvements.
-
Instrument everything. Every model call should log its inputs, outputs, latency, cost, and confidence. This is your audit trail and your optimization dataset.
-
Design for model swaps. The model landscape changes every quarter. Build your pipeline so that swapping a model for a better one is a configuration change, not a rewrite.
-
Stop waiting for AGI. The capabilities you need are already available. The question isn’t whether AI is smart enough — it’s whether your architecture is organized enough to use what’s already there.
The most expensive hire you’ll never need is the one you’re waiting for instead of building the team that’s already possible. And while you’re thinking about how specialist AI stacks challenge vendor lock-in, consider the lock-in playbook frontier labs are running — because the polymath fallacy and vendor dependency are two sides of the same coin.