Prompt Engineering Is Dead. Long Live Prompt Engineering.
By LumaVista Team


Remember when everyone was sharing “unlock GPT-4’s hidden powers” prompts on Twitter? You’d see screenshots of these elaborate incantations — “You are an expert in X with 20 years of experience, respond as if you were speaking at a TED talk” — and people would treat them like cheat codes. Copy, paste, marvel at the output, share the thread.
That was 2023. It feels like a decade ago.
Those magic prompts are worthless now. Not because prompting doesn’t matter — it matters more than ever. But the specific tricks, the weird token hacks, the “jailbreak” sequences that circulated like underground mixtapes? They stopped working the moment the next model update shipped. They were exploiting quirks, not leveraging principles.
Here’s the thing nobody’s saying clearly enough: the death of prompt tricks isn’t the death of prompt engineering. The skill didn’t die. It grew up. And if you think you don’t need it anymore because “the models are smart enough now,” you’re about to hit a ceiling you can’t see yet.
The magic prompts of 2023 exploited quirks. Modern prompt engineering leverages principles — and the gap between lazy and thoughtful prompting has only grown wider.
What prompt engineering used to be
In the early days — 2022 through early 2024 — prompt engineering really was a form of token hacking. You weren’t communicating with an intelligence. You were manipulating a pattern-completion engine that happened to produce surprisingly coherent text.
The field had its own canon. Wei et al. published the chain-of-thought paper in 2022, showing that simply adding “let’s think step by step” to a prompt dramatically improved reasoning performance. That phrase wasn’t instruction — it was an incantation. It worked because it shifted the probability distribution toward tokens associated with logical reasoning in the training data. The model wasn’t actually thinking step by step. It was generating text that looked like thinking step by step. And that was enough.
System prompts became another lever. You could tell GPT-3.5 it was a “senior data analyst” and get measurably better outputs on data tasks — not because the model assumed a persona, but because the prefix biased its token predictions toward the vocabulary and patterns used in analytical writing. Few-shot examples did something similar: instead of explaining what you wanted, you showed the model three examples and let it pattern-match its way to the right output format.
All of this worked. It was also fragile, model-specific, and fundamentally about coaxing an engine that couldn’t quite understand what you meant. You weren’t briefing an analyst. You were programming a very strange computer by typing English words into it and hoping the probability distributions landed in your favor.

Why people say it’s dead
The “prompt engineering is dead” crowd has a point — and it’s worth hearing them out before we push back.
Modern models genuinely are better at understanding natural language. You don’t need to say “let’s think step by step” when the model already reasons through problems by default. Claude, GPT-4o, Gemini — they handle ambiguity, follow complex instructions, and produce structured output without the elaborate scaffolding that earlier models required. The gap between a carefully engineered prompt and a casual question has narrowed considerably.
Then there’s the agent argument. When you use a system that decomposes your task into sub-tasks, routes them to specialized models, and synthesizes the results — do you really need to “engineer” anything? The system handles the hard parts. You just type what you want.
And the tooling argument: prompt templates, prompt management platforms, auto-prompt optimizers — the infrastructure is eating the craft. Why hand-tune a prompt when DSPy can optimize it programmatically?
These are legitimate observations. The bar for “good enough” prompting has dropped. You can be lazier than you could in 2023 and still get decent results.
But “decent” isn’t the same as “good.” And “good” isn’t the same as “exactly what you needed.”
Why it’s actually more alive than ever
Here’s what the “prompt engineering is dead” narrative misses: as models get more capable, the ceiling rises faster than the floor.
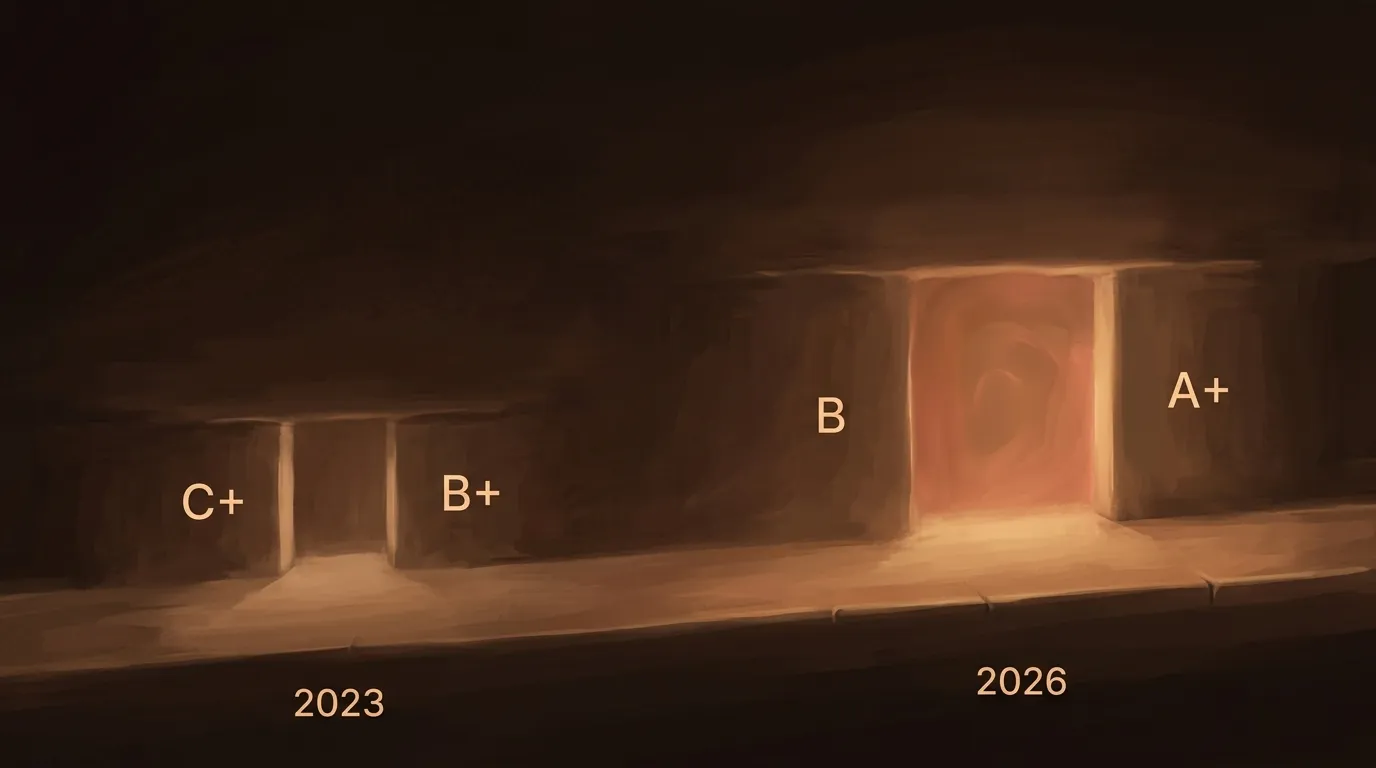
Yes, a vague question produces better output than it used to. But a precise, well-structured question produces dramatically better output than it used to. The delta between lazy and thoughtful prompting hasn’t shrunk — it’s grown. A 2023 model might have given you a C+ answer to a vague prompt and a B+ answer to a great one. A 2026 model gives you a B answer to a vague prompt and an A+ to a great one. The floor came up. The ceiling went higher. The gap widened.
The skill shifted from syntax to semantics. You’re no longer tricking a model into behaving a certain way. You’re briefing a system that genuinely understands your intent — but only if you actually express that intent clearly. Think of it like the difference between working with a junior intern and a senior consultant. With the intern, you give step-by-step instructions because they can’t fill in gaps. With the consultant, you give a clear brief and let them work — but a vague brief wastes their expertise just as badly as it wastes the intern’s time.
The new prompt engineering isn’t about hacking tokens. It’s about thinking clearly enough to communicate what you actually want. That sounds simple. It isn’t. Most people have never had to articulate their research questions, creative constraints, or analytical frameworks with the precision that modern AI rewards. The bottleneck moved from the model to the human.
A 2023 model gave you a C+ for a vague prompt and a B+ for a great one. A 2026 model gives you a B for vague and an A+ for great. The floor rose, but the ceiling rose faster.
The new prompt engineering
So what does modern prompt engineering actually look like? Here are five techniques that work across models, across tools, and that won’t break with the next update — because they’re rooted in communication principles, not token manipulation.
1. Specify output format
Before: “Summarize this article.”
After: “Summarize this article in three bullet points. Each bullet should be one sentence, start with a bold key takeaway, and include a specific data point from the article.”
The difference isn’t cleverness — it’s specificity. The first prompt gives the model infinite degrees of freedom. The second constrains the solution space to exactly what you’ll actually use. You wouldn’t tell a graphic designer “make it look good.” You’d give them dimensions, brand colors, and placement requirements. Same principle.
2. Define constraints
Before: “Write a project proposal for a new mobile app.”
After: “Write a project proposal for a new mobile app. Budget ceiling is €50,000. Team is two developers and one designer. Timeline is 12 weeks. The app needs to work offline in areas with poor connectivity.”
Constraints aren’t limitations — they’re information. Every constraint you add eliminates a category of irrelevant output. Without them, the model gives you a proposal that might assume a team of twenty and a budget of half a million. With them, it gives you something you can actually hand to your stakeholder.
3. State what you DON’T want
Before: “Explain blockchain to me.”
After: “Explain blockchain to me. Skip the cryptocurrency angle entirely — I’m interested in supply chain applications. Don’t use analogies involving banks or ledgers. Assume I understand distributed systems but not consensus algorithms.”
Models are trained on enormous corpora where certain topics have dominant framings. “Blockchain” triggers cryptocurrency associations. “AI” triggers Terminator references. Explicitly stating what you don’t want is often more effective than describing what you do, because it prunes the most likely — and least useful — default responses.
4. Give context about yourself
Before: “What are the tax implications of selling a rental property?”
After: “What are the tax implications of selling a rental property? I’m a self-employed individual in Germany, I’ve owned the property for eight years, and I’m trying to decide whether to sell this year or next. I have no other capital gains this year.”
The model doesn’t know who you are unless you tell it. And the right answer for a German freelancer is completely different from the right answer for an American corporation. Context about your situation, your expertise level, and your decision-making timeframe turns a generic response into a relevant one.
5. Decompose complex asks
Before: “Help me plan a conference.”
After: “I’m planning a two-day technical conference for 200 attendees. Let’s start with just the venue requirements. What criteria should I use to evaluate potential venues, given that we need breakout rooms for workshops, reliable AV for live demos, and accessibility compliance under EU standards?”
Complex requests produce superficial responses because the model spreads its attention across too many sub-tasks. By decomposing the ask yourself and focusing on one piece at a time, you get depth instead of breadth. This is especially powerful with models that support extended conversations — each response builds on the previous one, and you end up with a detailed, coherent plan instead of a shallow overview.
Agents change the game, not the principle
If you’ve used agentic AI systems — tools that break your question into sub-tasks, assign them to specialized models, and synthesize results — you might think the five techniques above are obsolete. After all, the agent does the decomposition for you. It handles the routing. It manages the constraints.
True. But agents don’t eliminate the need for clear communication — they amplify it. When you give a vague instruction to a single model, you get one vague output. When you give a vague instruction to an agent system, you get multiple vague outputs synthesized into a confidently vague result. The agent faithfully decomposes your unclear question into unclear sub-questions and answers each one with the same lack of direction.
The principle holds: garbage in, garbage out. The mechanism changed — you’re no longer optimizing a prompt, you’re optimizing a task description. But the underlying skill is identical. Define what you want. Specify constraints. State what you don’t want. Give context. Break complex asks into focused ones.
Agents do not eliminate the need for clear communication — they amplify it. A vague instruction to an agent system produces multiple vague outputs synthesized into a confidently vague result.
If you’ve read our piece on asking AI better questions, you’ll recognize this as the same intelligent hill framework applied at a different altitude. The levels of prompting quality (zero-shot, one-shot, few-shot, chain-of-thought) still describe the spectrum from lazy to precise. Agents just moved the trailhead higher up the mountain. You still have to climb.
The same question, three ways
Let’s make this concrete. Say you’re researching EU AI regulation for your company’s compliance team. Here’s the same research question at three quality levels, and what each one actually produces.
Level 1: Vague
“Research EU AI regulation.”
What you get: a broad, Wikipedia-style overview of the EU AI Act. Its history, its goals, its general categories of risk. Accurate, probably. Useful? Not really. You could have gotten this from the first Google result. The model gave you everything because you told it nothing about what you needed.
Level 2: Decent
“Summarize the EU AI Act’s requirements for high-risk AI systems.”
Better. Now the model focuses on a specific category within the regulation. You’ll get the classification criteria, the conformity assessment requirements, the transparency obligations. It’s genuinely informative. But it’s still a summary of publicly available information, organized by the regulation’s structure rather than by your needs.
Level 3: Excellent
“Identify the three highest-impact EU AI Act provisions for financial services compliance teams. For each provision, include: the specific article number, what it requires in practice, the enforcement start date, the maximum penalty for non-compliance, and one concrete example of how it would affect a credit-scoring algorithm.”
Now we’re talking. This prompt constrains the scope (financial services), specifies the output structure (three provisions, five data points each), grounds it in a concrete use case (credit scoring), and tells the model exactly what “impact” means in this context (enforcement and penalties). The output is something you can actually put in front of your compliance officer.
The difference between Level 1 and Level 3 isn’t sophistication. It’s clarity. The Level 3 prompt doesn’t use any tricks. It doesn’t invoke chain-of-thought or few-shot examples. It just communicates what a thoughtful human actually needs — with enough precision that the model can deliver it.
That’s the whole game. That’s prompt engineering in 2026.

Clear thinking is the last mile
The irony of prompt engineering’s evolution is that the skill it requires now — clear, structured communication — is the same skill that makes you effective at everything else. Writing a good prompt is the same discipline as writing a good project brief, a good research question, or a good email to your team. The AI just makes the feedback loop faster. A vague brief to a human colleague wastes a week. A vague prompt to an AI wastes ten seconds. You can iterate faster, but you still have to learn the lesson.
Prompt engineering isn’t dead. It just stopped being about AI and started being about you.
At LumaVista, our planner agent handles task decomposition automatically — it breaks your research question into focused sub-tasks, routes them to the right tools, and synthesizes the results. But the system is only as good as the question you start with. A clear, well-constrained research question unlocks the full depth of multi-agent analysis. A vague one gets you a vague result, faster.
The models will keep getting smarter. The tricks will keep dying. But the ability to say exactly what you mean? That’s the skill that compounds.