How to Ask AI Better Questions
By LumaVista Team


You ask ChatGPT to recommend a marketing strategy for your new product. It gives you a confident, detailed plan. Sounds great. You close the tab, reopen it the next morning, and ask the exact same question. Different answer. Different strategy. Different confidence.
That’s not a bug. That’s how the thing actually works.
If you read our breakdown of the DRAG framework, you already know which tasks to hand off to AI. But knowing what to delegate is only half the equation. The other half? How you ask. And most people are doing it wrong — not because they’re lazy, but because they’re treating AI like something it isn’t.
AI isn’t a calculator — it’s a probability engine
For 300 years, Newton had us convinced the universe ran like clockwork. Predictable. Certain. Then Heisenberg came along in 1927 and showed that at the quantum level, the universe exists as a cloud of possibilities — not fixed outcomes. As theMITmonk puts it in his breakdown of what he calls “the intelligent hill,” we need to make a similar mental shift when working with AI.
You type 2 + 2 into a calculator and get 4. Always. Every time. AI doesn’t work that way. It’s a probability engine — it predicts the most likely next word based on patterns it absorbed during training. Ask it the same question twice, and you’ll get two different answers. It’ll happily make things up if you don’t stop it. It’s brilliant on Tuesday and confused on Wednesday, and on both days, it refuses to admit when it doesn’t know something.
This means you can’t just ask AI a question the way you’d ask a person. You have to architect your questions. And there are distinct levels to this — each one a camp on the climb up what theMITmonk calls the intelligent hill.
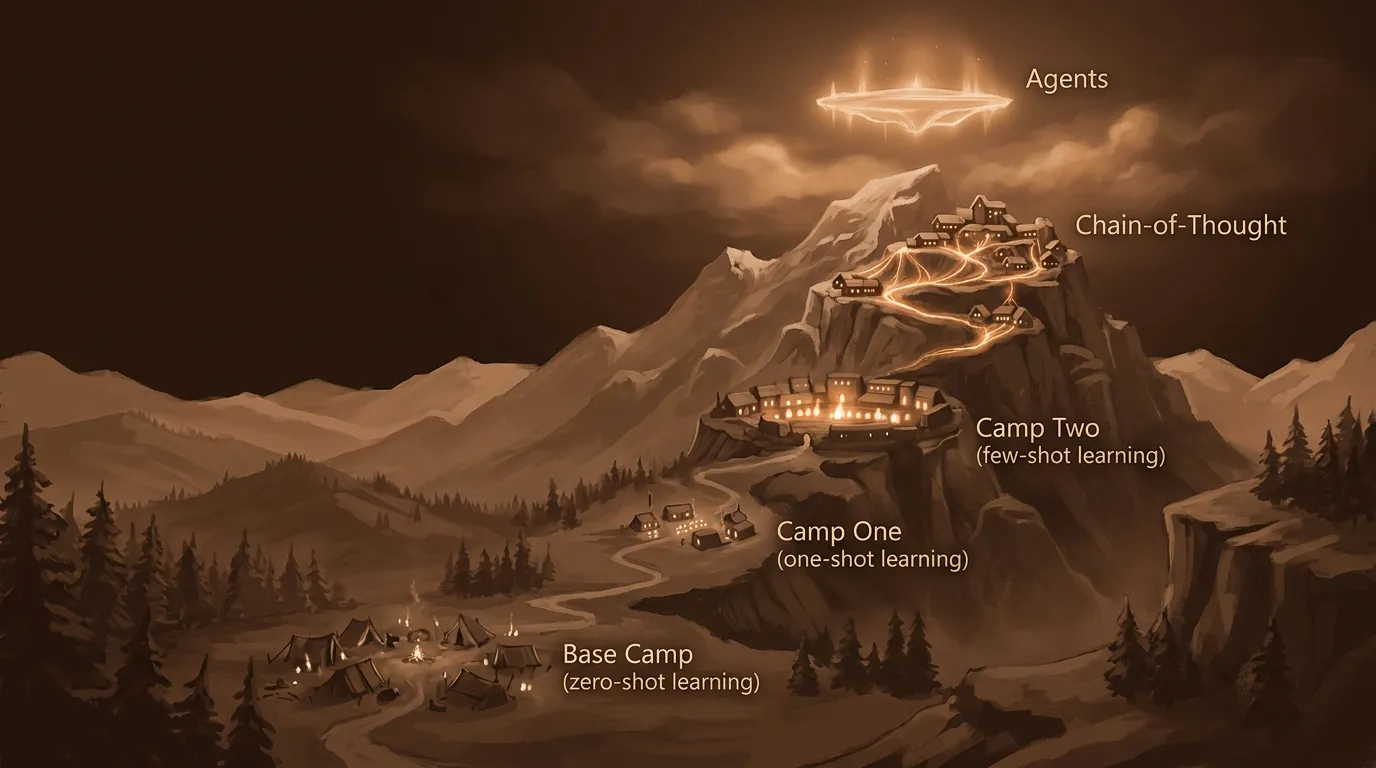
You type 2 + 2 into a calculator and get 4. Always. AI does not work that way. It predicts the most likely next word — and two runs of the same prompt can yield completely different answers.
Level zero: rolling the dice (zero-shot prompting)
This is where most people live. You open ChatGPT and type something like:
“Give me the best new business idea.”
AI will happily respond. It’ll sound confident. It might even tell you why it’s the greatest idea in the world. But you’ve given it nothing to work with — no context, no constraints, no examples. You’re essentially rolling a die and hoping to win.
The output? Generic. A grab bag of whatever patterns were most common in the training data. You’ll get “start a SaaS company” or “launch a sustainable fashion brand” — the AI equivalent of a fortune cookie.
Zero-shot prompting isn’t useless. It’s fine for quick brainstorming or getting unstuck when you’re staring at a blank page. But if you actually care about the quality of what comes back, you need to climb higher.
Level one: give it a style guide (one-shot prompting)
Here’s the first upgrade, and it’s dead simple. Instead of asking blind, you give AI one clear example of what you want.
“Write a LinkedIn post about remote work. Use this specific post as a style guide:”
[paste an example post you like]
That’s it. One example. And already, the output is dramatically better. The model isn’t guessing your tone, your length preference, or your audience anymore. It has a reference point. It’s the difference between telling a contractor “build me a house” and handing them a photo of a house you like.
You’re still not in great territory — one example can only do so much. But you’ve moved from dice-rolling to at least aiming at a target.
Level two: ground the model (few-shot prompting)
Now things get serious. Instead of one example, you give AI three or more. This lets it identify patterns — your voice, your structure, your logic, your preferences. The technical term is “grounding,” and it means the model stops fantasizing and starts working from reality.
“Here are five of my previous presentations. Write a new presentation on [topic] that matches my tone of voice, structure, and level of detail.”
Three examples tends to be the sweet spot in practice. Below that, the model might latch onto a quirk in your single example. With three or more, it starts to see what’s consistent across your work — which is actually you.
Here’s a pro tip straight from theMITmonk: after providing your examples, ask the AI to explain the pattern back to you first. Something like, “Before you write anything, tell me what patterns you notice in these examples.” This forces the model to articulate what it’s doing, and it forces you to learn something about how your own brain works. You’re being smart about being smart.
The quality leap from zero-shot to few-shot is enormous. You go from generic AI slop to output that actually sounds like it came from your desk.
Level three: slow it down (chain-of-thought prompting)
This one’s counterintuitive. AI is fast — that’s the whole point, right? But speed is exactly the problem. When you let it race to an answer, it takes shortcuts. It skips steps. It hallucinates.
Chain-of-thought prompting — first described by Wei et al. in 2022 — is a fancy name for a simple idea: make the model show its work. Force it to think step by step before it gives you a final answer.
“Do not refine my research report yet. First, list the top three most impactful areas of improvement. Tell me why you think so and suggest how we’d address each. Think step by step. Show me your thinking for each step.”
That last line — “show me your thinking” — is the most important part. It changes the entire computation. Instead of jumping to a conclusion, the model has to build a chain of reasoning, and each step constrains the next one. The result? Fewer hallucinations, better logic, more useful output.
Think of it like this: if you asked an employee to analyze a report and they immediately blurted out “it’s fine!” you’d be suspicious. But if they walked you through what they checked, what they found, and what they’d change — you’d trust their answer a lot more. Same principle.

The fifth level: agents change everything
Here’s where the climb gets interesting. Everything we’ve covered so far — zero-shot through chain-of-thought — is about making a single AI model give you better answers. You’re polishing one brain. But what if instead of one brain, you had a team?
That’s what AI agents are. Instead of one model trying to be an expert at everything, you have specialized agents that each handle one piece of the puzzle. A researcher finds information. An analyst evaluates it. A writer synthesizes it. A critic checks the work. They hand off to each other like a well-run team.
According to Salesforce, AI agents helped drive €62 billion in global sales during Cyber Week 2025 alone — influencing 20% of all purchases through personalized recommendations and conversational service. This isn’t a future concept — it’s already here.
The breakthrough is that agents don’t just improve one prompt. They restructure the entire problem. A single prompt to a single model is like asking one person to research, analyze, write, and fact-check in a single breath. Agents split that into discrete tasks, each handled by a specialist that’s optimized for exactly that kind of work.
AI agents drove €62 billion in global Cyber Week 2025 sales alone. This is not a future concept — multi-agent systems are already reshaping how work gets done.
Why multi-agent beats better prompting
Here’s the punchline, and it’s the reason the intelligent hill metaphor matters: you shouldn’t have to climb it manually.
With single-model prompting, the burden is on you. You’re the prompt engineer. You have to know about zero-shot vs. few-shot vs. chain-of-thought. You have to remember to say “think step by step.” You have to attach examples. You have to ground the model. Every conversation, every time. One lazy prompt and you’re back to rolling dice.
Multi-agent systems flip this. Instead of you climbing the hill, the system climbs it for you. Your natural, imperfect, human question goes in at the top. The system handles the decomposition, the grounding, the verification, and the reasoning — automatically.
It’s the difference between learning to be a master chef and having a kitchen full of specialists who each do one thing brilliantly. You still decide what to cook. But you don’t have to worry about whether you’re holding the knife right.
Instead of learning to be a master chef, imagine a kitchen full of specialists who each do one thing brilliantly. You decide what to cook. They handle the technique.
How LumaVista climbs the hill for you
This is exactly what LumaVista’s multi-agent architecture does. You ask a question in plain language — no prompt engineering required — and the system automatically handles every level of the intelligent hill:
- Planner agent — Takes your question and decomposes it into sub-tasks, automatically applying chain-of-thought reasoning. You don’t have to say “think step by step” — the planner does it by design.
- Search agents — Fan out across the web to find real sources, automatically grounding the model with real data. This is few-shot prompting happening behind the scenes, except the “examples” are live, verified information instead of whatever you remembered to paste in.
- Human-in-the-loop checkpoints — The system pauses at critical decision points so you can steer. You’re not just hoping the AI got it right — you’re validating as it goes.
- DAG visualization — You can see the entire reasoning process laid out as a directed graph. Every agent, every decision, every source. Full transparency into how the answer was built.
The result? You type a normal question. You get a cited, structured, validated answer. No prompt engineering. No climbing. The system does the work that would’ve taken you four levels of progressively sophisticated prompting to achieve on your own.
What to do now
-
Try the staircase yourself. Take a question you recently asked AI. Re-ask it using one-shot (with an example), then few-shot (with three examples). Notice the quality difference — it’s dramatic.
-
Add “show your thinking” to every important prompt. This single phrase improves output quality more than any other prompting trick. Make it a habit.
-
Use the “explain it back” technique. After giving AI examples, ask it to describe the patterns it found before generating anything. This catches misunderstandings early.
-
Stop polishing prompts — start grounding them. Attaching real documents, real examples, and real data beats clever wording every time. Context trumps cleverness.
-
Recognize when you’re rolling dice. If your prompt is a bare question with no context, examples, or instructions — you’re at zero-shot. That’s fine for brainstorming. It’s not fine for anything that matters.
-
Consider whether you need the hill at all. If you’re spending more time engineering prompts than doing the actual work, you’ve outgrown single-model AI. Multi-agent systems exist precisely so you don’t have to be a prompt expert to get expert-level results.
-
Try LumaVista. Your natural question goes in. Automatic decomposition, grounded research, validated reasoning, and a cited report come out. The intelligent hill — climbed for you.
This is Part 2 of our “Working Smarter with AI” series. In Part 1: The DRAG Framework, we covered which tasks to delegate to AI and which to keep for yourself. Up next: how to verify AI’s work so you can actually trust the output.
The “intelligent hill” framework referenced in this article comes from theMITmonk’s breakdown of how the top 1% use AI. We’ve expanded on his prompting levels with concrete examples and connected them to multi-agent architecture.